Integration process monitoring - collect events with Azure
In this post I will show how to implement simple event collection by using Azure: publish endpoint for events, enrich information with reference data and persist to storage. Obviously this is only a small part of the whole monitoring solution, but hopefully will demonstrate that rocket science is not needed to get started.
Example process
For this example, I will use imaginary invoicing process that has four steps that send events:
- New invoice received
- Invoice transformation started
- Invoice transformation completed
- Invoice sent to operator
As you can see, very simple, but will do the job as an example.
Collecting events
The goal is to implement functionality that I described in my previous post:
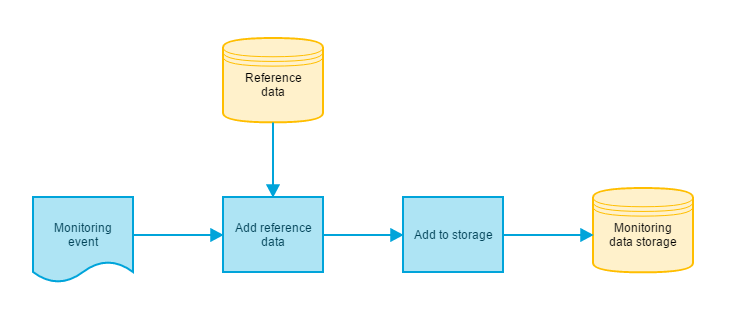
The idea is to keep the actual event content as simple as possible and enrich the information with reference data. This way it is possible to alter the meaning of the events without touching the code of the event source (for example you want to change the priority of the event when you identify a serious bottleneck in your process.). You could argue that why enrich the event data at all before persisting it? That is a valid point and depending on the use case it might be better to match the event and it’s reference data only when presenting the data in the UI. What I have found is that you generally don’t want to alter the past. Therefore I think that it is better to attach the event to the reference data at the time of the event. This way ytou are able to track the changes back in history and changing the reference data doesn’t affect the event that are alredy persisted.
Event data model
In this example I will use following data model for the event:
public class Event
{
public Guid Id { get; set; } //Unique identifier for the event
public string EventId { get; set; } //Identification for this particular process event
public string InstanceId { get; set; } //Identifier to connect events from the same process instance
public DateTime Timestamp { get; set; } //Timestamp of the event
public List Metadatas { get; set; } //Additional info for the event in Key-Value pairs.
}
As you can see, there is not much information needed from the event source. In real life, I would probably add some additional fields for errorhandling situations. Also one thing that I have been going back and forth with is the process identification. Should the event contain the process id or should it be added as part of the metadata. The situation when this becomes relevant is when you want to be able to handle multiple versions of the same process. Let’s say you add another step to you process. You probalby don’t want to update every single event with new EventIds. At the moment I don’t have the ultimate answer locked for the process id and version, so for the sake of simplicity, those are added in with the reference data.
And how about the raw payload data? In integration process monitoring, it is often useful to see the actual message contents in case of troubleshooting. I suppose that it could be added as part of the event itself, but it would make the logic much more complex and grow the event sizes as there can be any number of data formats from flat files to cat videos. A simpler solution would be to have a separate data storage and only to add reference for the payload as part of the event. That can already be done with the metadata part of this data model:
public class EventMetaData
{
public Guid Id { get; set; } //Unique identifier for this metadata instance
public string Key { get; set; } //Key for the metadata, for example InvcoiceID
public string Type { get; set; } //Type for the metadata value, could be useful for example in reporting scenarios
public string Value { get; set; } //Actual value of the metadata
}
I this example events are sent in Json format for the event processing.
Azure components
To implement this kind of functionality, few components from Azure are used:
An endpoint for receiving the events is needed and for this we use Azure Event Hubs
“Event Hubs is a highly scalable publish-subscribe event ingestor. It can collect millions of events per second, so that you can process and analyze the massive amounts of data produced by your connected devices and applications.”
Sounds perfect.
For analyzing and handling the enrichment of the received information, there is component called Stream Analytics
“Stream Analytics provides out-of-the-box integration with Event Hubs to ingest millions of events per second. Stream Analytics processes ingested events in real-time, comparing multiple real-time streams or comparing real-time streams with historical values and models.”
Stream analytics can match the event data with reference data and combine the two for various outputs including another Event Hub or some of the Azure Storage options (Azure SQL, table storage or blob storage). In this example I will use table storage, but any of the other options would be as easy to use.
Managing Event Hubs and Stream Analytics is still done in the classic Azure Portal (https://manage.windowsazure.com). Event Hubs can be found under the ServiceBus tab and adding new event hub is a matter of few mouse clicks:
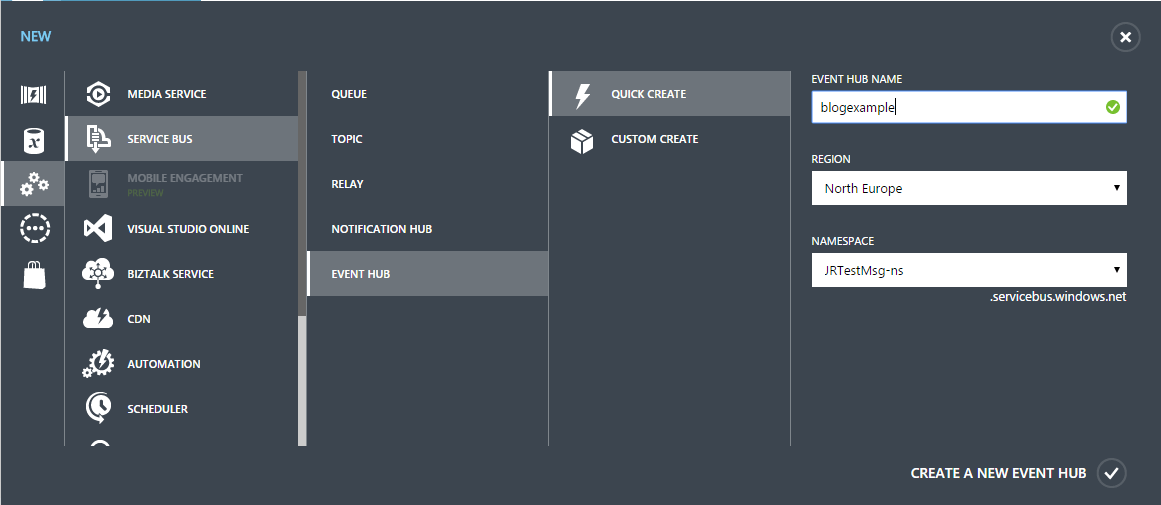
That’s it! Now you have a public endpoint ready for receiving events. All you need is to pick up the connection string from the newly created Hub’s config settings and this part is done.
The process with Stream Analytics is not much harder, but you need to have an existing Azure Storage account for storing the monitoring data. I created two Stream Analytics jobs: one for handling the enrichment of the event information and another for storing the medatadata. Both of these are stored in separate table storage tables:

The way Stream Analytics works is that you define inputs, query and outputs for the job. The query language is very T-SQL like so if you have been working with databases at all, it shouldn’t take long to get the wheels spinning. In this example I will concentrate only to a small subset of the features Stream Analytics provides, there are lots of other cool things you can do with the queries. As inputs for my first job I have the Event Hub that I created and a json-file in the blob storage of my storage account. The reference data content looks like this:
[
{
"EventId" : "event-1", // Key for matching the reference data to the event
"ProcessName" : "Invoicing process", // Name of the process
"ProcessId": "Invoicing", // Id of the process
"ProcessVersion": 1, // Version of the process
"State": 1, // State for the process instance, when this event is triggered, in this example I have used following: 1 = Started, 2 = In progress, 4 = Completed
"Type" : "Info", // Event type, could be anyting. For example "Info", "Warning", "Error". Could also be numeric enumeration
"Description" : "New invoice received" // Description of the event.
},
// reference for other events goes here
]
The key used to match incoming event to the reference data is EventId. There could be any number of additional fileds in the reference data (like priority). As an output I have configured a table storage table with InstanceId as the partition key and TimeStamp as the row key. The query to combine the inputs to output is rather simple:
Basically you just take the data from the defined inputs and join them to an output. As you can see, I have combined the process identifier and version into one column in the output. The query editor in Azure portal let’s you test drive your query by entering sample inputs. This way it is easy to see whether your query works as expected.
Configuring the Stream Analytics job for the metadata handling is quite similar to the handling of the enrichment. This time we only need one input, which is the same Event Hub as in the previous job. And again the output is a table storage table (different one though). In this output I used InstnaceId as the partition key and metadata’s key as the row key. Getting the query for the metadata parsing took a while as I was a bit uncertain how to parse the incoming event and get to the metadata. In the end also this query is rather simple and looks like this:
That’s it! We are ready for some event storm!
Creating events
I followed the example given in the Getting Started Guide of the Event Hubs and there really is not that much black magic involved. I created a simple console app that just sends predefined process events with some delay between the events:
As you can see, sending an event is dead simple. Connecting to the Event Hub takes only few lines of code and the rest is just for creating the Event objects. Now let’s see what happened.
As a result of running the console app sending the events, I now have data in both of my table storage tables. Event data enriched with the reference data is in one table:

Just by sending very litte information with the events to the Event Hub, I now have all the additional information attached to the events that I need for building a meaningful user interface. With this method, I don’t have to worry about the event details like descriptions at the development phase. Those can be added from the reference data when the process is finalized.
I also have the metadata with a reference to the InstanceId of the process in the metadata table:

Summary
In this post I have demonstrated how you can implement a simple event collection system with Azure technologies in matter of minutes. Creating components for receiving events, adding reference data to the events and persisting the information with event metadata in key-value store can be done with only few lines of code and in less time that it takes to drink two cups of coffee. With this approach my solution is build on top of Microsoft’s capacity to handle millions of events per second, which should be more than enough in most cases.
Obviously this solution would not quite yet pass the UX-criteria that you would have for an integration monitoring system, but maybe that’s something for the future posts.

My name is Juha Ryhänen. I’m interested in everything related to productivity, remote work, automation and cool gadgets. This is my personal website where I write about the things I find interesting. Maybe you do too? [More]
Contact:
[email protected]